From Zero to HA Hero: Building On-Prem Kubernetes Clusters with Ansible
After eight years as a Customer Success Engineer at Naverisk, living almost entirely in Windows, I felt something needed to shift. I loved solving problems, helping clients, and managing systems, but I needed something harder. Something messier. Something new.
This realization led me to the world of Kubernetes. Transitioning from a Windows-centric role to building and managing Kubernetes clusters was no small feat. I had to acquaint myself with Linux systems, containerization, orchestration, and a plethora of tools and concepts that were previously outside my comfort box. It was a steep learning curve, but one that reignited my passion for technology and innovation.
In this article, I’ll share my journey from the familiar grounds of Windows to the dynamic landscape of Kubernetes. I’ll delve into the challenges I faced, the lessons I learned, and how I leveraged tools like Ansible and Rancher to build robust, on-premises Kubernetes clusters. Whether you’re considering a similar transition or simply curious about the process, I hope my experiences provide valuable insights and inspiration.
New Skills, New Life: Learning Linux While Everything Else Was On Fire
As I prepared to pivot from Windows-heavy systems work into more Linux-native territory, I enrolled in the Linux Foundation’s System Administrator course. I knew I needed a solid foundation, no pun intended, but I didn’t quite expect the mental gymnastics that came with it.
The course was… a lot. Don’t get me wrong, it was well-structured, but the authors were blunt: “You will not pass the certification exam with course content alone.” That warning turned out to be dead serious. The course gave you the map, but no vehicle. You had to build your own and fill in wide knowledge gaps along the way. Which meant diving into man pages, exploring obscure config files, and breaking (then fixing) many things in my home lab.
And here’s the kicker: I wasn’t doing this in a vacuum.
At the same time, my wife was pregnant. We had just moved into a new house that needed renovation, top to bottom. I was still working full-time in a demanding support role.
And then boom! The baby arrived.
Between diapers, baby cries, SSH sessions, broken configs, tailing logs and service restarts, I kept grinding. Sometimes I studied Linux at 3AM while keeping watch on the kid and playing with my wife’s hair(she sleep well when I do that). Sometimes I was debugging a service, a script or an install while the sound of my baby boy crying in his mom’s arms echoed from the next room. It was chaotic and painful. It was exhausting. But it was also kind of exhilarating. This wasn’t just a career upgrade; it was a life transformation. I wanted more for myself, but even more for my new family. I knew upgrading myself would upgrade them too.
New Role, New Reality: Trial by Fire
Eventually, my efforts paid off and I landed the job I now hold. The interview went great, the team seemed solid, and everything felt like the natural next step in my career. And it was, just with one small twist: it was go-time from day one.
We were a small team, and there wasn’t much room for hand-holding. I had to dive deep and fast. No slow ramp-up, no months-long onboarding. Just “Here’s what we need—go build it.”
There was a 6 month probation period, where I was not allowed full admin privileges, but that ended in 1 month when hungry for information and lack of team-mate support(small team, remember), I demanded I get the rights to the kingdom’s keys. And I was given said keys, then started working.
And that’s when it hit me. I now have goals. Official goals! Every. Quarter.
“We need production-grade, on-prem Kubernetes clusters. Use Ansible. Build or get a new Ansible platform. Your pick!”
Cue minor internal crisis.
The team had trialed Ansible Tower. It was $30k/year. I saved that in my 2nd month, by switching to Ansible AWX. Had to build the think properly, using K8s. All guides pointed to K3s. I had to learn K8s.
From scratch!
Sure, I’d messed with Kubernetes before, but only in my home lab. Now I was in an enterprise environment.
I had a folder of copy-pasted kubectl commands and some vague memory of tinkering with services and pods. But little did I know… I had been playing with K3s the whole time. That was my entire “experience.” I didn’t even fully grasp the difference between a control plane and a worker node, let alone know what “HA cluster with VIP failover” meant in the real world.
And Ansible? I only had a simple playbook that run yum update on a few VMs. That was about it.
But the mission was non-negotiable: ✅ Build clusters. ✅ Make them reproducible. ✅ Make them rock-solid. ✅ Oh—and do it on bare-metal, on-prem infrastructure.
It was one of those “sink or swim” moments. Spoiler: I decided I wasn’t going to drown.
So I fucking swam. Not even Jesus could catch me.
Learning By Doing (and Googling… a Lot)
Before anything else, I had to bootstrap the infrastructure. We weren’t using Terraform or Spacelift back then. No IaC, no GitOps. Just me and Ansible, deploying VMs on bare metal.
That’s where the real learning began. I went down the Kubernetes rabbit hole:
What’s the deal with Docker vs Containerd?
How do systemd slices and cgroups actually control resource limits?
What are CNIs, and why does Flannel sometimes just… stop working?
How do you bootstrap a control plane, generate join tokens, and manage cert expiry?
What are kubeconfigs, and why do they feel like secret scrolls?
At one point I had so many tabs open on certificate chains and API server arguments, I felt like I was studying for bar exams, not building infra.
But slowly, it clicked. I built scripts, then turned those scripts into Ansible playbooks. Then into a workflow.
Eventually, it was one click.
The “Fun” Bit: HA Clusters with Virtual IPs
The final boss was an HA setup: 3 synchronized control plane nodes and several workers, all load-balanced behind a single Virtual IP.
We used:
HAProxy + Keepalived on two separate nodes, all built and configured by Ansible, dynamically.
VIP failover between them in case one dropped. Again, part of a dynamic, logic based configuration.
It worked.
It booted, joined, and scaled. Everything that had to talk to the cluster hit the VIP, which routed to healthy control planes. And it was all automated.
I could go from bare VM to HA K8s cluster with a single command. 10 fucking VMs all provisioned, configured and tied together. One click.
4 years later, my clusters still run, with not issues. We migrated all workloads from Windows workers, running on individual servers, to K8s pods, running on one cluster. Money was saved, efficiency was served and everything clicked together nicely.
I still maintain that stuff.
Rancher + AWX = Final Form
We weren’t done yet.
Once the clusters came online, they had to be managed. So I automated Rancher cluster registration using their API. No UI clicking. Rancher became our control tower.
At this point we were finally in a good place. Git-based updates, Rancher governance, AWX automation. And beefy servers that meant we didn’t even bother with autoscaling.
Each control plane and worker had its own blade. We had power. We had control.
It’s interesting to see that a lot of systems engineers and admins still use traditional methods of deploying new servers to an already existing and established infrastructure.
This can take many hours to complete and is a process that can be prone to mistakes, leading to an overall ineffective work ethic and low productivity efforts.
What I do instead, is keep true to my mission statement and try to make every process a bit easier. If it can be automated, I will automate it.
If you want to replicate this setup, you’ll need a VMware vSphere environment with full admin access, as well as an Ansible AWX instance that is able to connect to said VMware environment.
Connecting Ansible AWX to your VMware environment is trivial, provided you have the necessary permissions and network access to do so.
Anyway, let’s get to work!
Step 1. Setup the VMware connection
You’ll need to login to your vcenter using an admin user.
Once logged in, open the side-menu, then select Administration.
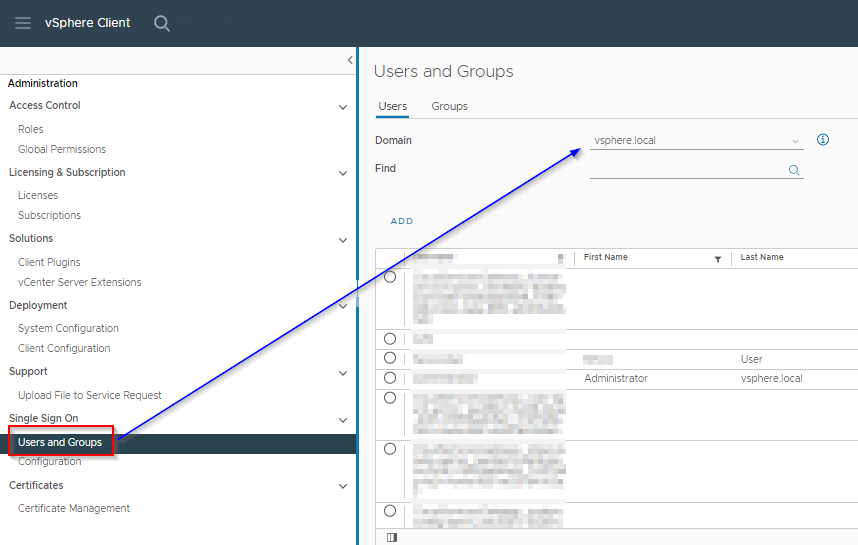
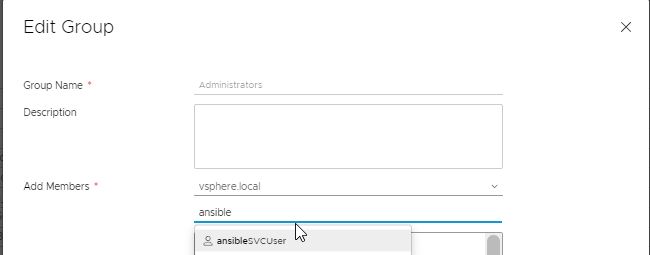
In the Administration section, select Users and Groups, then select the domain as vsphere.local. You may chose to select any of the other available domains, however since this is basically a service user, we don’t need to go through the process of creating a dedicated domain user. A local user will do just fine. Of course, think whether your vCenter is accessible publicly; If it is, then security is paramount.
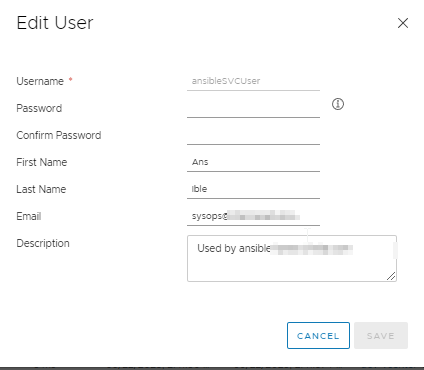
Go ahead and create your user. Here’s mine.
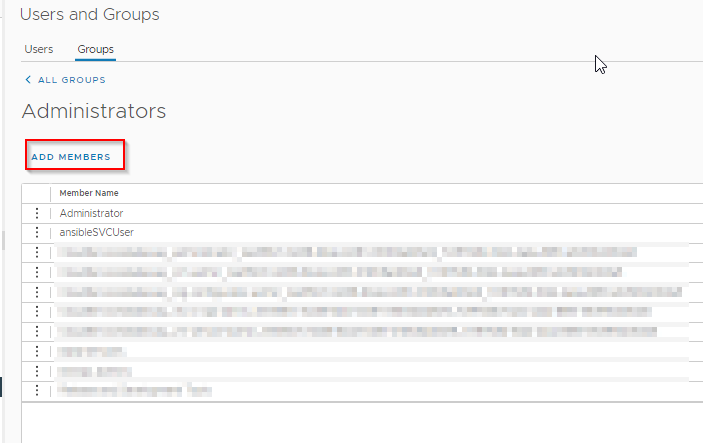
Once the user is created, move over to the Groups tab, select the group you want to add your user in. depending on what tasks it is going to perform, then add it, by clicking the Add Members button, then using the search bar to search for your newly created user.
And that’s it on the VMware side.
Now, you may want to fine-tune the permissions of the user, at some point, based on the tasks it usually performs. Mine creates, manages and deletes VMs and other resources. We use it for a lot of things, so we need it to be as powerful as it can be.
Step 2. Setup the Ansible AWX Credentials
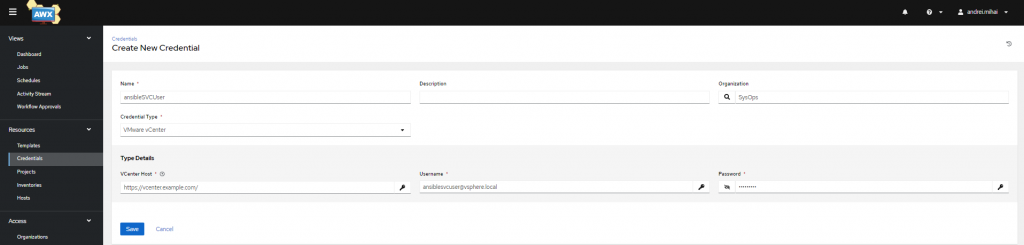
If you’re here, you should already know how to login to your AWX and do most things, so go ahead and a new VMware vCenter Credential.
The quality of this image is low, but you get the gist.
Once you have the credentials in, you can create a new Inventory and put the credentials to use.
Step3. Sync your VMware Inventory
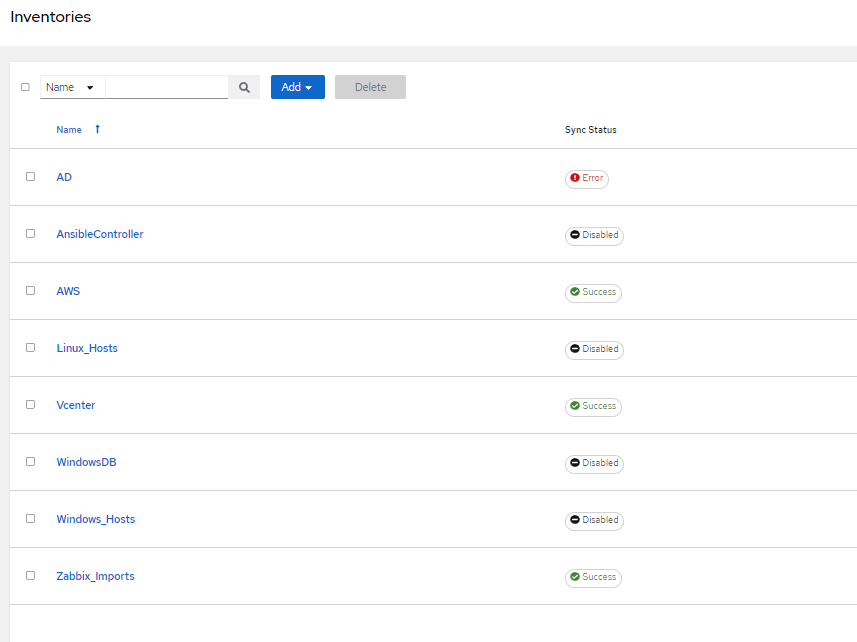
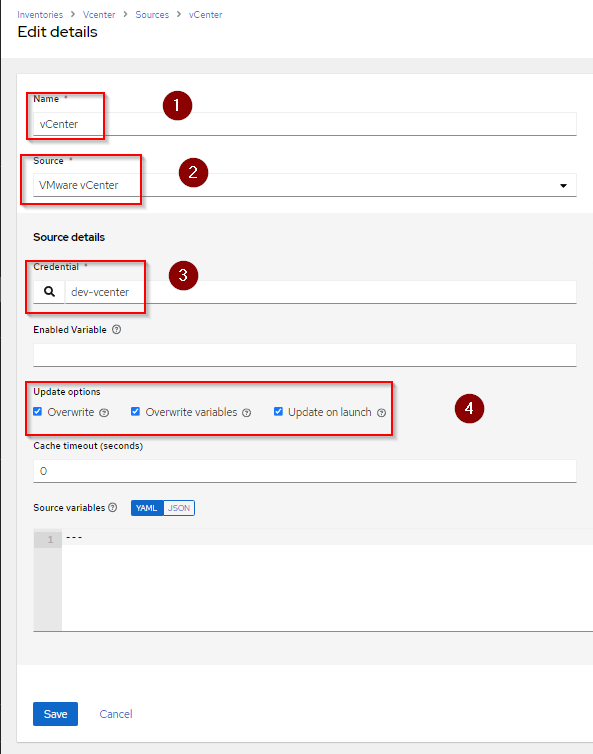
Go ahead and create a new Inventory. Name it Vcenter, just so you know which one it is.
Here are mine. You can see some have a Sync Status of Success. These are dynamic inventories that update every time I target them with a job.
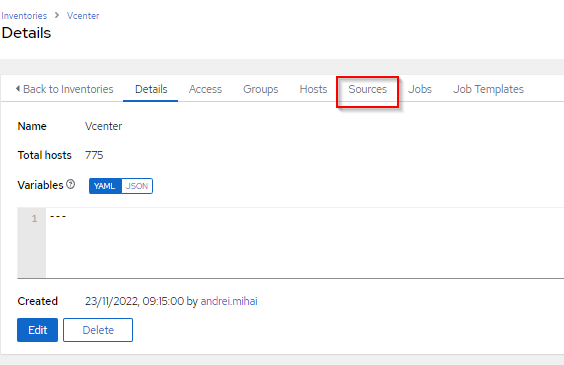
Once you created your base inventory, go ahead and create a sync source, in the Sources tab.
The setup is very simple. All you need is a Name, a Source, which is readily available, the Credentials you previously created and chose what happens when the inventory syncs.
In my case, I update the inventory on launch. What this means is every time I run a job on this inventory, the inventory updates.
We also overwrite variables, because things might change, on hosts between syncs.
You also want to Overwrite hosts, because you might have hosts that are no longer offline and hosts that were offline and are now online. The same is valid for hosts that are new or hosts that have been deleted.
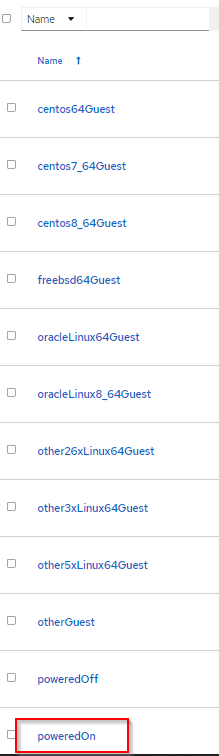
The maintainers of the inventory sync were awesome enough to allow the sync to auto-create groups of hosts, based on the guest OS. Unfortunately, the guest OS groups do not contain only powered on VMs. They contain all the VMs from that guest OS category.
However, there is a group called poewredOn, which contains all the powered On VMs.
This is nice, as you can target that group and then apply wildcard limits for the vms you want to target in a job.
This is, as I will later show you, quite efficient.
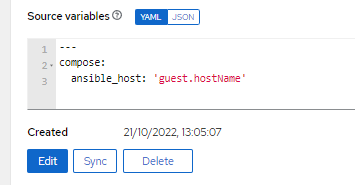
Now, there is a catch. When you sync your vCenter inventory, Ansible will pull all the hosts, by their VM Name and their instanceUuid value and concatenate those as the Inventory Ansible Host Name, which by default, will be used as the ansible_host value which is used by your jobs. In some cases, the primary IP of the VM is used instead.
If you want to avoid that and instead use DNS names, then you should be able to use the following to your Source variables:
Warning:
This article does NOT contain a TL;DR version. Everything in this article is 100% relevant, informative and educational. You're here to stay, wether you like it or not. If you attempt to close this tab without reading everything, your mouse might catch fire and your desk with burn. Or not. It all depends on the chance of that to actually happen.
You were warned.
Off topic
Time flies. Seems like only yesterday I wrote my last post. Reads date stamp: 20 September 2021…
Well, it does and since then and until now, a lot has happened.
I’ve learned a lot of new things, I’ve met a bunch of interesting people, I’ve experimented with a lot of technologies and on a more personal level, my kid is growing like a champ. And us with him.
Ain’t life wonderful?
One of the first things I did last year, was to get into Ansible. I had experimented a bit with it in the past, but not much.
I’m not an expert, by all means, but I know my way around it pretty well.
I also got ok-ish at basic kubernetes stuff too. I know enough to get myself into trouble, but also get myself out of trouble. Those who know me, know what I mean. Wink! They don’t. All of my friends have no understanding of this… alien language.
I managed to deploy Zabbix in HA mode and although it had some performance issues at first, with a database growing too large and items queueing like crazy, I sorted that too. Almost.
Oh, this was part of a migration from an older version of Zabbix to the newest. It was all quite new to me but it all worked fine in the end.
All supported by, you guessed it; Ansible! You didn’t guess it, did you?
I actually want to write two whole articles about that, as it was something so simple, yet so elusive. Not the migration. That was easy. The database size and queueing stuff. That was stupid to happen in the first place and mainly due to poor documentation.
In simple terms, Ansible AWX is a platform that allows you to run Ansible playbooks through a nice web-ui.
It does a lot more than that, in fact. Something we’ll probably explore in the future, but today I want to show you how to deploy Ansible AWX on a kubernetes clusters, in a few, easy steps as well as provide some of the facts that come with this type of deployment.
I will try to split this into blocks so that it is easier to parse and understand.
I hope that by the end of the article you’ll have a working AWX instance. Laughs maniacally
AWX can be installed on any modern Linux distribution that supports kubernetes. You can use a VM, WSL2 with systemd(tricky to use but works, if you are absolutely out of your mind), or a bare-metal server.
Choosing your environment
Now, to start with the serious stuff.
You can run it on 2CPUs and 4GB RAM easily, although you might see some hits in performace from time to time. On such systems, I highly recommend dedicating the system only to AWX.
We will build AWX with an external database. For the project we need postgresql 14. If possible, I recommend using a second server for the database. If not, local works too.
My own home instance tends to be a bit slugish on the following system, although this is not a dedicated server for the AWX services.
Optiplex 9020 does not support botting from a SSD, so this thing runs on spinning rust.
For this article, we will use Ubuntu 22.04, however, I have successfully used Fedora 35-36, Oracle Linux 8.5 and Rocky Linux 9 to host AWX.
For those that want to skip reading this article, you can find my own repo with full instructions here. Note thatkubeDeploy.sh works on Ubuntu while kubeDeploy_worker.sh works on RHEL/Fedora based systems. That particular script was written on Fedora 35 and was tested on Fedora 35, 36 and 37, Alma Linux 8 and 9, Rocky Linux 8 and 9 as well as Oracle Linux 8.
The k8s groundwork
The most basic AWX installation requires a single node Kubernetes cluster. This is also called the Control Plane, in Kubernetes nomenclature.
A single node Kubernetes cluster does not require much in terms of resources.
I made things very easy to use and understand at the same time, when I created the kubeDeploy.sh script. The script works as is. No need to make any changes.
Perhaps uncomment the commented lines to install the previous to last version of each package and exclude them from being updated. This if fairly important, so it’s fitting I would place this instruction here.
If you’re already using Ansible, you might also want to consider using my very own playbook, although some minor tweaking is required, as it’s rather personalized.
As per the official docs, 2GB RAM/2 CPU are enough for a basic cluster. More never hurts, except maybe your wallet.
Some other things you need to take into account when creating a kubernetes cluster, that you may miss if not specified.
Disable swap. This gave me plenty of headaches at one point. Looking at you, zram.
Disable the host firewall OR add every rule required. With a firewall disabled, for a non-public interface, you don’t need to worry about adding rules every time. On a public interface, though, things change.
The playbook handles swap and makes sure the firewall is disabled. The script does the opposite. Feel free to add your own syntax to the script to achieve the task. I won’t sue you.
As I use the playbook(s) for this task, I could not be bothered with tweaking the script. The script(s) are for non-ansible people and are more of an orientative, educational way of automating k8s deployments.
The quick and easy way is to just run the script. Remember, that the script was made for Ubuntu, so if you’re on SUSE or RHEL, you’ll need to adjust the syntax. Most of the steps for RHEL systems can be found in the kubeDeploy_worker.sh script.
For other distributions like Manjaro, find your own way.
The commented line in this script has a purpose. Can you figure out what it is? Hint: control plane and workers should to be on the same version. A fitting place for another important bit.
So provided you went ahead and just ran the scripts, you more than likely ran into some issues. If you didn’t then either you know what you’re doing or you followed someone else’s instructions. If neither, then you’re in luck, my friend. You should play the lottery.
Try not to mess this up
When it comes to databases, I’m a sucker. I know a few queries here and there, I understand the principles and I try to do my best, or at least I’m good at googling. Heck, last week I partitioned a live 300+GB mysql database with no disruptions. In my sleep. No, I didn’t mean I dreamt it. I just left the process running overnight.
I did dream I was The Joker, one night though. Weird.
So the point is to install a supported version of postgresql.
Aligning with the official docs, postgresql 12 is a minimum, although my script installs postgres 14. I don’t have the script in my own repository, for some unknown reason, but I am willing to share it here, for now. This is for RHEL based systems, so you’ll need to adjust for Ubuntu. There are some commented lines that will also help you upgrade postgresql if you’re running on an older version.
if [ -z $1 ]
then
echo -e Please run this script as follows:\n ./pg14.sh yoursupersecretpassword \(optional\)your_database_file.sql
#update
else
sudo dnf update -y
#install deps
sudo dnf -y install gnupg2 wget vim tar zlib openssl
#get repo
sudo dnf install https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm -y
#disable old pg
sudo dnf -qy module disable postgresql
#install new pg
sudo dnf install postgresql14 postgresql14-server postgresql14-contrib -y
#init new pg
sudo /usr/pgsql-14/bin/postgresql-14-setup initdb
#enable the service.
sudo systemctl enable --now postgresql-14
# note that the default location for all files has changed from
# /var/lib/postgresql/data/pgdata/ to /var/lib/pgsql/14/data
# if you're on a distribution that's not fedora or opensuse downstream, then...perhaps it's in /etc/.
# luckily, I have your back.
# we need to do a few things, before we make the database available to k8.
# first, we need to change local connection controls. This allows us to run psql commands locally.
sudo sed -i.bak 's/^local.\{1,\}all.\{1,\}all.\{1,\}peer/local all all trust/' /var/lib/pgsql/14/data/pg_hba.conf | grep trust$
#then we need to allow remote connection controls, for the newly created database. This allows us to run psql commands remotely. pods and tasks need this.
#DO NOT DO THIS ON A PUBLICLY FACING SERVER
sudo bash -c "echo host awx awx 0.0.0.0/0 md5 >> /var/lib/pgsql/14/data/pg_hba.conf" | grep awx
#then we need to update the posgresql.conf to listen for external connections. This is so we can connect to the DB, from our pods.
sudo sed -i.bak "s/^#listen_addresses = 'localhost'/listen_addresses = '*'/" /var/lib/pgsql/14/data/postgresql.conf | grep listen
#restart to apply changes
sudo systemctl restart postgresql-14.service
#create a database.
psql -U postgres -c "create database awx;"
#create the role.
psql -U postgres -c "create role awx with superuser login password '$1';"
#test the connection.
psql -U awx awx -h localhost -c "\c awx;\q;"
#You are now connected to database "awx" as user "awx".
#^means succes.
echo "We are done. We can proceed with the K8s setup now."
#if we have a database that we need to restore, then we need to perform a few more steps:
#1. restore the DB
#
if [ ! -z $2 ]
then
psql -U awx awx < $2
#
#2. Done.
fi
fi
#NOTE: When restoring a database, the next AWX deployment will likely also upgrade the database, so the deployment can take a while.
#NOTE2: Don't forget to claim your secret-key secret from the old AWX instance. You'll need this for the AWX deployment to connect with your restored database.
Just read through the comments if you don’t know that the script does. Mură-n gură…
I hope you made that work for yourself. If not, tough luck. Did I not tell you that this is the road to perdition? Must’ve forgot…
Many learn by doing, so this is your chance. If you already did and already know, then great. You’re a star!
Once this step is complete, you have a K8s cluster running and a database ready for your AWX service. With these two requirements complete you’re half-way to 30% there.
What comes next is the interesting part. And obviously I have a script for that too, but desert always comes after the main course, so we’ll have to dig in first.
Manifests time!
This is the pure kubernetes part that most despise. I did too, but then I learned to love it. A sort of Stockholm syndrome, if you will. From a bird’s eye view, this is what you need:
Let me explain.
Ignoring the .sh scripts, the following files do the following things:
loki.yaml – this is the equivalent of awx-demo.yaml in the official documentation. It defines your type of instance, the HTTP port it will be accessible on(use 30080, trust me), type of ingress, hostname, etc. This file is responsible for the deployment of your AWX service. I suggest reading the docs to better understand what each specification does. I named it loki, because that is what the server name is.
loki-tls.yaml – This is your TLS secret. You will need one if you want to access the service over port 443. Go here to learn how. You can use a self-signed cert. Note that the name of the secret needs to be specified in the main file, as the ingress_tls_secret.
loki-postgres-secret.yaml – It contains the connection details for your database, which you created in the previous step. If the pg14 script did its job, you’ll only need to specify the host and the secret in this file. Note that the name of the secret needs to be specified in the main file as the postgres_configuration_secret.
ingress.yaml – It creates an ingress point which allows you to access your new AWX site over port 443, instead of the standard nodePort you have selected in the main manifest. More on that later. As in never.
krb5.yaml – It creates a kerberos configuration and attaches that to your awx instance as a volume mount, so that you can manage domain joined Windows hosts. Tweaking is required as I have used an example configuration. I recommend that you copy the /etc/krb5.conf contents from one of your domain-joined linux hosts and paste it under thekrb5.conf: |section. You don’t need this if you’re managing non-domain joined devices, or only Linux hosts in a LAN. So for your home-lab, you can remove this file or ignore it completely. By the way, if you want this configuration to work, you’ll probably need to use my own Execution Environment.
deploy.yaml – Is this. It creates an ingress-controller. You’ll need this for https access.
kustomization.yaml is the manifest file that lists all the files needed for the deployment. We use kustomize for this task. Kustomize is installed by the awxSetup.sh script.
Now that we’ve described all files, it’s important to make sure we have everything we need setup correctly.
For example, the kustomization.yaml manifest looks like this:
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
# Find the latest tag here: https://github.com/ansible/awx-operator/releases
- github.com/ansible/awx-operator/config/default?ref=0.29.0
- loki-postgres-secret.yaml
#uncomment below if you have updated and want to use the kerberos extra volume/mounts
# - krb5.yaml
- loki-tls.yaml
- loki.yaml
# Set the image tags to match the git version from above
images:
- name: quay.io/ansible/awx-operator
newTag: 0.29.0
# Specify a custom namespace in which to install AWX
namespace: awx
Note that the krb5.yaml file is commented.
When you run the kustomize command, kustomize will apply each manifest in the order they appear in the file. So if you place loki.yaml before loki-postgres-secret.yaml, when the awx service is created it might not know about the connection details manifested in loki-postgres-secret.yaml and your deployment might fail. My experience tells me that the deployment restarts and when it does, it re-checks everything and finds the connection details. Also my experience: – You do know you put those in that order in there for a reason, right? Right?!
So, as per my own personal tradition, I spend hours writing a piece of text that really explains nothing, as I trully know nothing and anyone who reads it, just has to click a few links and gets all the good stuff served on a silver platter.
Good ol’ Andrei.
As a bonus, the script can also upgrade your AWX instance. Do make sure to include a pg_dump in there, if you care about your saved stuff, otherwise, just use it as is.
I’m not saying upgrading breaks stuff. It doesn’t. But just in case it might…
This is the bit that always gets you the latest version.
if [ ! -d $HOME/awx/k8awx/awx-operator/ ]
then
git clone https://github.com/ansible/awx-operator.git
else
rm -rf $HOME/awx/k8awx/awx-operator/
git clone https://github.com/ansible/awx-operator.git
fi
cd $HOME/awx/k8awx/awx-operator/
ver=$(git describe --tags --abbrev=0)
cd $HOME/awx/k8awx/
sed -r -i s/\([0-9]\{1,\}.\)\{2\}[0-9]\{1,\}/"$ver"/g kustomization.yaml
Thank me later!
One last thing. After the ingress.yaml is applied, you will be able to access your site for a short period. Then, you won’t. I’m not yet sure what causes this. All I know is that awx-operator sees that a change has occurred and restarts the installation, which also modifies your ingress by removing its annotation.
So what you have to do is to wait a few minutes for the deployment to finish, then edit the ingress and re-add the annotation.
You can use kubectl patch or kubectl edit for that.
It doesn’t matter which you use. Your ingress should look like this when your un kubectl get ingress -n awx-o yaml Note the bold bit.
The main access details are here. Use those to get your initial secret, then change the password. Or you can just copy/paste this command. That should work.
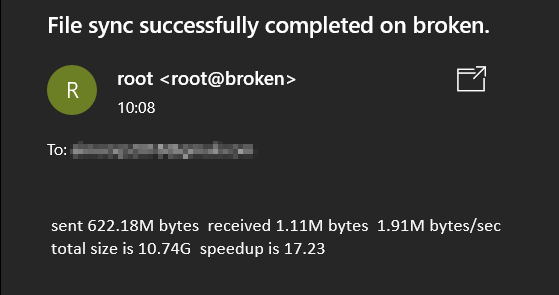
So last week, I was thinking of creating as systemd timer, that triggers a service, that runs a script, that takes backup of the whole system, using rsync and emails me a quick 2 line summary.
Alright. That was intentional.
Some perspective; The HDD I’m running the system from has had a BAD X written on it with a black marker, as it’s an old hdd of mine, that had some bad blocks which were impacting performance, quite a bit, but now works great(after some linux magic) so I want to keep everything backed up, as frequently as possible, just in case.
This is today’s result, for example, sent to my gmail address.
The hostname is relevant
I had this thing pretty much figured out in my mind, from start to finish.
backup script syntax:
Zoom & Enhance, to see the full syntax
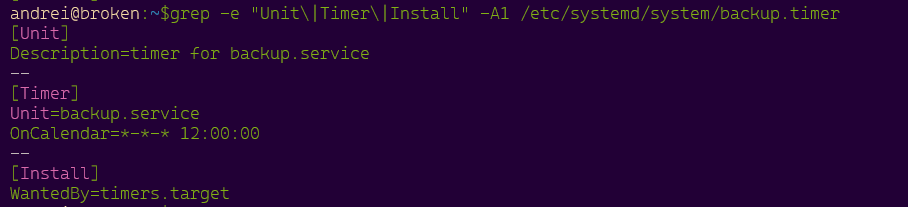
systemd.unit structure:
systemd.timer structure:
permissions(rwx) and all the other dependencies.
who needs the h…
I reach home and I start writing everything. Since I was using rsync, a basic service and a basic timer, this was quick work.
I gave the script a shot and as expected, it backups my whole system to another partition on the same drive and emails me the results.
I create the service and timer and I give them a shot too. My usual practice is to run something simple at first, like an echo, or just a quick email. Everything works as expected.
So now, it was time to put the everything together and enable the timer. I do that and I am surprised to see that I’m getting a Permission denied error on the rsync operations.
mmm what?
Now, every bit of information attached to the service, except the script, is owned by root. I know this may be bad practice in some circles, but this is one of my home lab test servers, so I can afford to be careless.
After checking a few logs, looking again and again at permissions, [successfully]testing the same solution on a few debian servers, I finally figured out what the problem is.
I was on Fedora. Fedora comes with SELinux enabled(setenforce 1).
Because I rarely work on non-debian systems, I was so used to not thinking beyond regular file permissions and attributes, that I completely forgot about SELinux.
Anyway, turns out that:
The service was not labeled correctly; Fixed by a simple “chcon –reference /etc/systemd/system/{somegoodknownworking.service, backup.service}
Rsync was being told to “talk to the hand”, by SELinux when not being ran outside a user session; Fixed by setting the correct boolean (setsebool -P rsync_full_access 1)
So what was the lesson I learned?
ls -laZ + chcon(or restorecon in most cases) + setsebool
I was creating a Unit file, that just runs a script to email me when one of my test server is online. Script was working fine on its own, Unit was very basic.
I plan on deploying this to production, so I needed a very light, very simple solution.
Script testing went well, Unit testing went well with another small script that just logged stuff, but when I updated the unit to run the actual notification script, the service would not start, with an ExecStart error.
I knew what the error meant, but I also knew there was nothing wrong with the script.
Being my off day and spending time with the family, I decided to just reboot and figure it out later, even though this is usually the last thing I do.
Things went so south after the reboot, that I could not fully boot anymore.
multi-user.target was gone for me and I was stuck in rescue.target.
Anyway, 30 minutes later, I finally figured out what was wrong:
Should have been pretty obvious. The bak file is the original.
Have you ever wondered why some things are hard and others are easy?
Well, think about it. Before toilets existed, can you imagine what it was like having to go to the bathroom?
Exactly. It was a lot more difficult and unpleasant than it is now. But then someone sat and thought about making it easy, not just for themselves, but for everyone.
This is what puts the world in motion. Ideas and innovation.
In the world of IT, there is plenty of both to go around.
And I’m not talking just about using the right tools for the right task. If you want to use Ansible or Terraform to automate something, you have to have someone that knows how to use these tools and know how to create the scripts needed to automate your deployments and configurations.